The Duck Is Plural Now: A Quack Deep Dive
DuckDB has always kept to itself. Not out of loneliness - by design. It's an in-process analytical engine, a library you embed straight into your Python, Go, or R program rather than a server you dial into over the network. Most of what makes it feel so good traces back to that one decision. Nothing to babysit, no connection string, no hop sitting between you and your data; you point it at a Parquet file on object storage, two lines later the engine is simply there, humming away inside your own process.
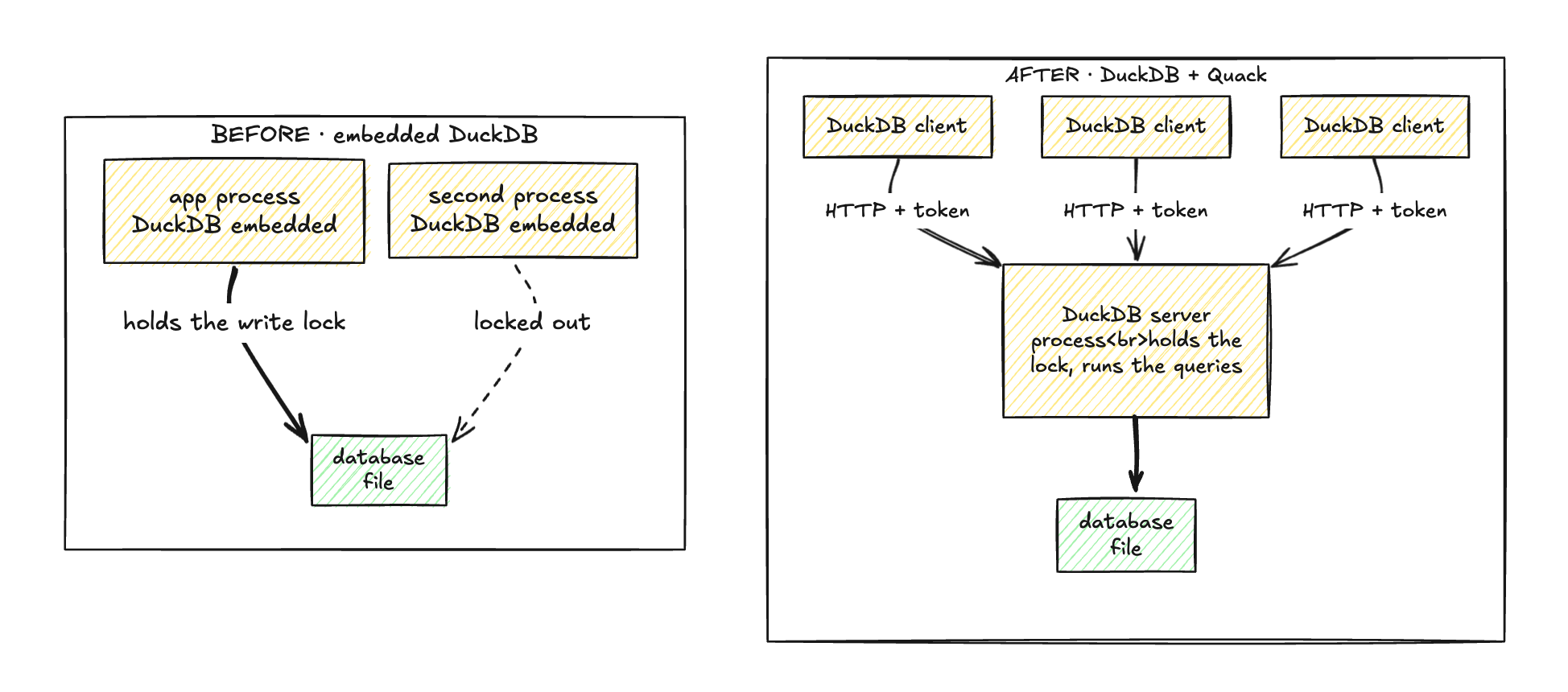
The bill for that design arrives the same way for everyone: sooner or later you hit one writer at a time. Open a database for writing and the file locks. Readers can pile on without trouble. Ask two processes to write at once, though, and DuckDB declines - reconciling two independent in-memory states is precisely the distributed-coordination headache it was built to sidestep.
Quack tries to make DuckDB plural without surrendering any of that. It lays a thin network surface over the engine, and suddenly two processes - or twenty - can mount each other's catalogs and query each other's tables as though everything were local. What makes it interesting is the angle of attack: it works from the inside. Same wire format DuckDB already speaks, same type system, same SQL dialect. At no point do you step outside the DuckDB world to use it.
Was that homogeneity a real feature, we wondered, or just a generous way of saying "narrow"? The only way to know was to try it. We brought up two DuckDB servers, aimed them at each other, ran federated joins across the pair, and watched for the places the idea held and the places it started to bend. What follows is everything that one decision - stay inside DuckDB - quietly settles on your behalf.
The whole thing fits in one ATTACH
The entire model fits in a paragraph. One DuckDB process plays server: it owns
the mutable state and answers queries over HTTP. Any other DuckDB process plays
client, runs ATTACH, and from that point on treats the remote thing exactly
like a local attached database - same schemas, same tables, same transactions.
Writes from every client funnel through the server and serialize there, which
keeps the single-writer rule intact even as a crowd of processes joins in.
Underneath that ATTACH, every interaction is just an HTTP round-trip. The
client trades its bearer token for a connection token, then each statement is one
POST; the server runs it on its own engine and ships the answer back as raw
DuckDB columns.
One word carries all the weight here: homogeneity. Because both ends are DuckDB, the protocol gets to be gloriously dumb. Nobody has to design a translation layer, babysit a second catalog abstraction, or negotiate some neutral interchange format. Whatever bytes the engine is already holding are the bytes that go straight onto the wire.
![]()
Two copies and no transform on the Quack path; an encode and a decode on the neutral one. That saved step is the whole performance story - and the reason the wire only ever speaks DuckDB.
Nearly every other interesting trait Quack has follows from that single call. Which makes it worth pausing to place that call against the long list of things that already let one database talk to another.
It's not the only way for two databases to talk
The shelf of "let a remote process talk to an analytical database" technologies is already crowded, and at a glance Quack looks like one more box to file next to the rest. Look again and it's a deliberately different shape - something that turns down the generality everyone else pays for, and spends the savings on one specific thing instead.
A quick, friendly tour of the neighbours:
- ODBC / JDBC give you network access to almost any database, at the cost of flattening rich types into a lowest-common-denominator catalog and dragging row-at-a-time semantics into a columnar world.
- Arrow Flight SQL is a clean, columnar, language-neutral protocol - a genuinely excellent piece of design. Its whole point is that any Arrow client in any language can read the bytes. You pay for that universality with a conversion on every hop, between your engine's internal representation and Arrow's IPC format. The conversion is fast; it is not free.
- Postgres-style foreign data wrappers were shaped for OLTP and bolt onto an existing planner; crossing engine and language boundaries was never their brief.
- Trino / Presto / Spark are full federated query engines. They bring their own planner and execution model and assume they should be in charge of how a query is decomposed across systems.
Not one of these is wrong. They're all answers to the same broad question: how do many different systems talk to each other? Quack asks something far narrower - how do two DuckDBs talk to each other? - and refuses to answer anything beyond it. Both ends are DuckDB, by assumption. The catalog you want is the one DuckDB already gives you, just stretched across a wire. And since the engine on either side is taken to be the right place to do the work, the protocol itself can stay thin.
That's a genuine design stance, not an oversight. And it's the question this whole piece keeps circling back to: commit to that narrow point, and what do you gain - what do you pay?
Four decisions hold the whole thing up
Four decisions shape how Quack feels day to day. None of them is unreasonable. But every one is load-bearing - knock it out and the character of the whole thing shifts underneath you.
Transport: plain HTTP
Quack rides on ordinary HTTP, optional TLS, one POST per logical request. Earlier drafts of the protocol flirted with WebSockets and Unix domain sockets before dropping both. The position it settled into is that ubiquity beats bespoke transport. Every load balancer, reverse proxy, and observability stack already speaks HTTP. Every browser supports it. Every cloud platform terminates it. All of that tooling comes to you for nothing.
What you pay is that HTTP is request/response down to its bones. So a long-lived "connection" in Quack isn't really a connection - it's a logical fiction laid over a stream of independent HTTP requests, held together by a token the server issues on first contact. Inside a single-replica deployment, that fiction holds up beautifully. The cracks appear the moment a load balancer can route two back-to-back requests from one client to two different replicas - which, of course, is exactly what production looks like. File that away; it's where the whole story eventually turns.
There's a road not taken here, too. gRPC over HTTP/2 would have handed Quack
bidirectional streaming, native flow control, and a tidier multi-message
lifecycle - along with codegen pipelines, protoc, fatter binaries, and the
usual awkwardness around browser interop. For a first network surface on
DuckDB, plain HTTP is the unglamorous right answer. Whether it stays the right
answer as the load climbs is an honestly open question.
Serialization: DuckDB's own bytes
Crack open an HTTP body and you'll find DuckDB's native columnar batch, written by DuckDB's own binary serializer. Not Arrow IPC. Not protobuf. Not JSON. The layout the engine already keeps in memory is the wire format.
That's the strongest performance argument Quack has. Nothing gets transcoded: a column on the server is poured directly into the wire, the bytes land on the other side, and the client reconstitutes its column from those very bytes. When both ends are DuckDB, that beats any protocol forced to detour through a neutral intermediate format - strictly, every time.
The trade-off is just the same coin flipped over. It's not a neutral intermediate format. Want to read Quack from something that isn't DuckDB? Then you're embedding DuckDB or writing a translator. The bet here is to be brilliant at one job rather than passable at a dozen. Reasonable - but it does mean Quack won't drift into becoming the integration layer for, say, an Arrow-based ML toolchain, not unless that toolchain decides to embed DuckDB itself.
Catalog: identical to local
Here's the decision that touches users most. Run ATTACH against a Quack server
and what comes back behaves identically to a local DuckDB database. Schemas,
tables, views, search paths, transactions - every one of them works the way it
does on your laptop. No second API to learn, no JSON schema to keep forever in
sync with something else.
This is what makes Quack feel small, in the best possible sense. It's also why Quack is a substrate and not a product: all it gives you is "another DuckDB, just over there." Whatever you stack on top of that is yours to design.
Trust: a bearer token, on purpose
Out of the box, authentication is a shared bearer token, and both the authentication and authorization steps are SQL-level functions you're free to override. Call it a deliberate "small now, extensible later" stance - plenty for a trusted boundary, nowhere near ready for the open internet. The fact that it's pluggable tells you where the maintainers expect richer auth to land: in extensions and sidecars, not baked into the core protocol.
Line those four choices up and the pattern jumps out. At every fork in the road, Quack picks whichever branch keeps the protocol thin and shoves the complexity outward - onto the engine, onto your infrastructure, onto some extension that hasn't been written yet. That, more than anything, is the personality of the thing.
The part the demos quietly skip: concurrency
Now for the part that decides whether you actually adopt this - and the part nearly every write-up tiptoes past: concurrency.
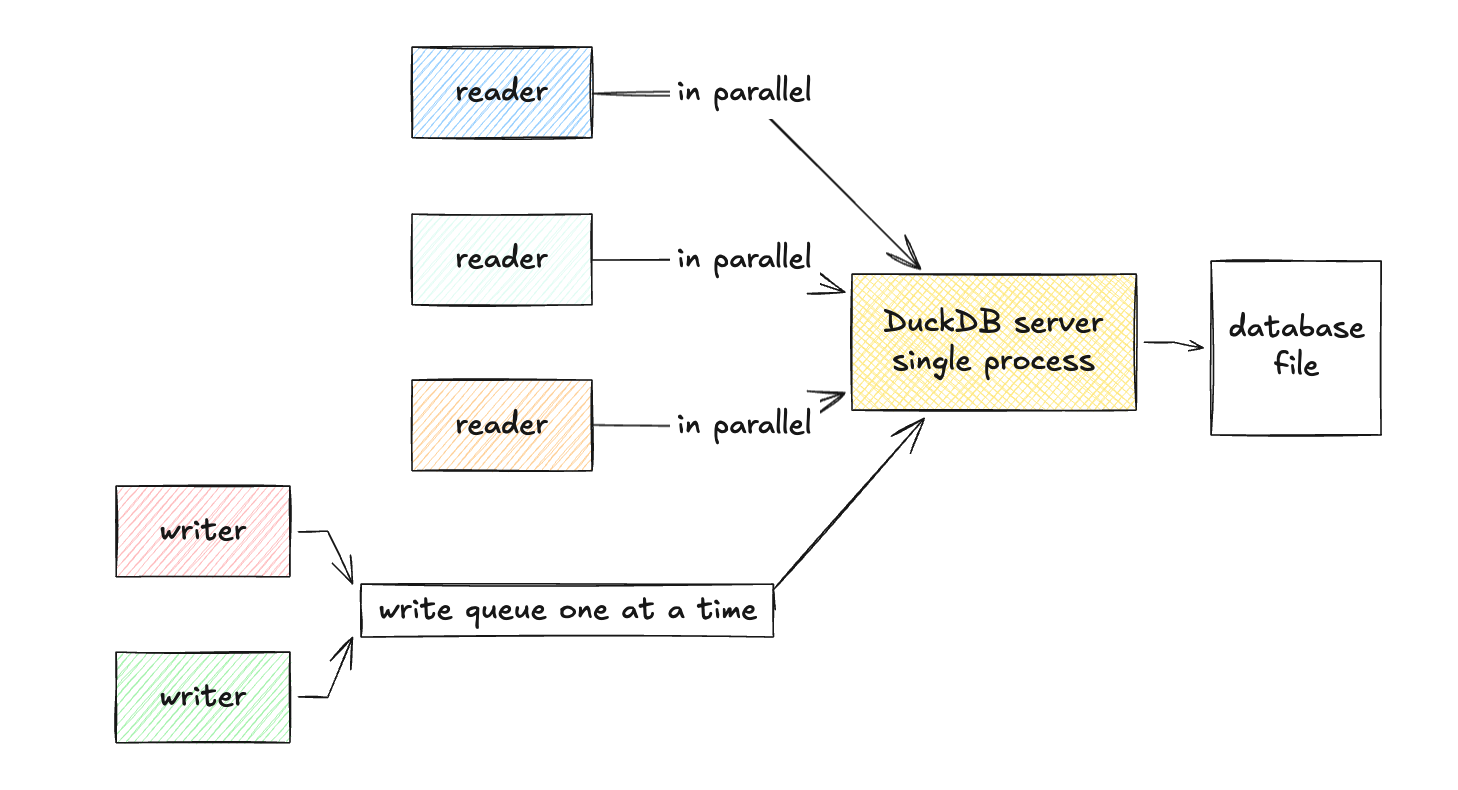
Whatever concurrency model DuckDB has, Quack takes the whole of it, unchanged. Many readers at once; a single writer per database at any moment; threads living inside one process. DuckDB still isn't a clustered database. It's an embedded engine that now happens to find itself running inside an HTTP server.
Spelled out plainly, the consequences look like this:
- Read throughput rises with the CPU cores on the server process. Pile on more readers and they simply share the thread pool and the engine's vectorized pipeline.
- Write throughput doesn't scale the way you'd hope. Concurrent writers serialize at the database level, so two clients writing through one server end up queued behind each other.
- Nothing is shared across processes. Point two Quack servers at the same DuckDB file and you corrupt it - DuckDB holds a process-exclusive lock, exactly as it should.
- Logical sessions carry state. Every
ATTACHopens a connection holding DuckDB session state (variables, transaction context), and that state lives in the server's memory and nowhere else.
For a data-publishing workload - lots of readers, one carefully curated dataset, writes that come around rarely - this is an outstanding fit. As "the production OLTP database behind a multi-tenant SaaS," it's the wrong shape entirely, and Quack never claims otherwise.
Our own experiment never tripped over this, and that's the point worth being honest about. Each client attached straight to a single server - one process on the other end, no load balancer in the middle - so every request in a session landed exactly where the session lived. The seam stays invisible right up until the day you add a second replica. Remember that a Quack "connection" is a logical thing, one token strung across many independent HTTP requests. The moment a load balancer can spread those requests across more than one replica, request N+1 can land on a replica that has never once heard of the session request N opened.
Today's remedy is about as unglamorous as it gets: sticky sessions - pin each client to one replica for the lifetime of its logical session. It works fine. But be clear about what it is. It's a deployment constraint, not a protocol feature. Quack is stateless on the wire and stateful in the server's memory at the very same time, and the seam between those two facts is precisely where real production topologies lean on it hardest.
If not a cluster, then what does scaling out look like?
No "Quack cluster" exists today, and nothing in the protocol hints at one. That doesn't mean the story ends at a single box, though. The architectures that can grow up around it all use Quack as connective tissue between single-process DuckDBs, and leave any sharing of the underlying storage to be handled outside the protocol entirely.

- Horizontal replication of read-only servers. Stand up N identical Quack servers behind a load balancer, each pointed at the same read-only DuckDB file (or its own synced copy). Keep clients sticky for the length of a session. Read workloads can do this today; the stickiness is the tax you pay.
- Read/write separation at the application layer. One leader takes writes while followers serve reads off a shared lakehouse format below. Quack knows nothing of the split - your application decides which server to attach for which job.
- Sharding by catalog. Park different DuckDB files behind different Quack
servers, let clients
ATTACHwhichever they need, and run federated joins across the shards on the client side. This is more or less what our two-server setup was, and it held up - with the honest asterisk that the join executes client-side, so the wire ends up carrying whatever the client couldn't push down. - A future stateless-request mode. Should Quack ever support queries that lean on no server-side session state - everything re-derived from auth claims on each request - it could drop the sticky-session requirement and sit happily behind a plain load balancer. That one's still speculation.
Not one of these makes Quack a clustered database. What they make it is the wiring that runs between several single-process DuckDBs.
One process to fall over - and why that fear dissolves
Right now, "use Quack" quietly means "trust one DuckDB process to stay upright." That's the same risk you carry with any single-instance embedded database, only now it's exposed over a network. The worry is fair - but the remedies are old friends, as long as you apply them on purpose:
- For durability, don't let the Quack server's local storage be the source of truth. Point it at a view over a lakehouse format you already trust - Iceberg, Delta, plain Parquet on object storage. From a durability standpoint the server goes stateless, and losing it loses nothing.
- For availability, run a handful of read-only Quack servers behind a load balancer, every one of them serving the same view. It's the OLTP world's read-replica pattern, dressed for OLAP scale.
- For writes, make your peace with one writer at a time. Either appoint a single server as the writer, or keep writes out of Quack altogether - push them onto a queue, batch them into the lakehouse, then refresh the view Quack fronts.
The trap is treating a lone Quack server as a multi-tenant, durable, shared database. It was never built for that, and its failure modes won't be kind when you find out. Treat it instead as a query gateway sitting on top of durable storage you already trust, and most of the single-point-of-failure dread melts away.
Three futures the design is pointing at
Follow where the design is pointing and three futures look plausible.
The USB-C of DuckDB. Take "DuckDB processes mounting each other" to its natural conclusion and you get a small mesh - a laptop attaches a team server, the team server attaches a curated lake, a notebook attaches all three, a CI runner attaches a fixture server. Everyone speaks one SQL against one catalog model, and the network becomes nothing more than a different physical route for the same logical operation. Down this path Quack barely grows at all. It stays small while the ecosystem around it - governance, observability, auth sidecars - quietly fills in.
The query layer for an open lakehouse. Make Quack the query surface, hand DuckLake the storage surface, and together they become an open, embeddable answer to the managed warehouse - Snowflake-shaped capabilities on a DuckDB-shaped footprint. For that to be more than a slide, though, Quack has to sprout a real federated planner. Predicate, aggregate, and join pushdown all have to mature; otherwise the wire turns into the bottleneck the instant the data gets large.
The browser ↔ backend bridge. Here's the one that's genuinely new. DuckDB-Wasm running in a browser, speaking the same protocol to a DuckDB on the backend, hands you "open SQL, columnar, browser-friendly, no REST API to design" in a single stroke. No other protocol today gives you all of that at once. Even if Quack never lands anywhere else, this use case stands qualitatively apart from anything you could already wire up with Arrow Flight or gRPC - a way to give users SQL over their own data without ever standing up a separate analytics-API tier.
What the idea can't do - and isn't trying to
None of these get patched in next week's release. They're contours of the idea itself, and they deserve to be named without flinching.
- No streaming, no incremental model. Quack is request/response, full stop. There's no "subscribe to this view," no "tail this table." Anything CDC- or event-shaped still wants Kafka, Debezium, or an actual streaming engine.
- No pub/sub, no fan-out. Ten clients asking for the same big result means the server computes and serializes it ten separate times. Nothing is materialized once and shared; nothing is broadcast.
- No native heterogeneous federation. DuckDB on both ends is baked in. Reach Postgres or Snowflake and you're loading DuckDB extensions on the server and exposing the result as views. It works - but it leaves Quack a homogeneous federation primitive, never a heterogeneous one.
- No language-neutral data plane. That's the serialization choice again, just worn as a limitation this time. A cost signed up for knowingly.
- The single-process ceiling is real. One Quack server tops out at exactly one DuckDB process's throughput, no asterisk. Vertical scaling hits a roof, and scaling horizontally is work you do at the application layer.
- The operational surface is young. The story for load balancers, gateways, and edge runtimes still has gaps to fill.
Read none of this as a case against Quack. It's the shape of the problem Quack signed up to solve, viewed from the outside.
and no, you haven't just built a free MotherDuck
Stand up a self-hosted DuckDB-on-a-server and it's tempting to declare you've built yourself a free MotherDuck. The two sit at different layers, though, and running them together misreads both.
Quack is an open primitive. It hands you "another DuckDB, over there," and then it stops. MotherDuck is a product, and it's built on exactly the harder problems that start where Quack leaves off - as its own breakdown of running DuckDB as a client-server system lays out in detail:
| Concern | Quack (the primitive) | A managed product (e.g. MotherDuck) |
|---|---|---|
| Identity | One shared token; every client has the same identity | Real multi-user accounts, SSO, service accounts |
| Sharing | All-or-nothing - you have the token or you don't | Granular shares to users, orgs, or the public |
| Storage / compute | Tied to one compute instance's storage | Separated; differential storage, time travel, clones |
| Scaling reads | Manual replicas + sticky sessions | Read scaling across instances, on demand |
Run your eye down that table and the relationship clicks into focus: a managed platform's entire pitch is the right-hand column - the very things Quack hands back to you. Quack's job is to make the primitive open and excellent. Everything above the "another DuckDB, over there" line - identity, sharing, separated storage, a serverless lifecycle - is still product work, whether a vendor ships it or you build it yourself. Calling Quack a competitor is a category error. It's the layer those products stand on, not a substitute for them.
The protocol is small. The idea is large.
Quack is a well-shaped idea. It puts its finger on a real gap - embedded analytical engines have no good way to talk to each other without shedding the very embeddedness that makes them worth using - and it plugs that gap with the narrowest, most coherent primitive that could possibly do the job. Protocol, catalog model, auth surface: all three are unambitious in the best way. They step out of your path.
The two questions that will actually decide where Quack goes have nothing to do with the protocol at all:
- Can it grow a federated planner without breaking its back? The thin-transport posture is perfectly comfortable while datasets stay small; the wire turns into the bottleneck the moment they don't. There's visible work upstream already, and the hooks for it live in DuckDB core. This is the inflection point to watch.
- Will it find a home you can name? The two clearest candidates today are DuckLake-shaped lakehouse plumbing and the WASM browser-to-backend bridge. Either one on its own justifies the protocol's existence - and both are still early days.
What we took away from the experiment:
Adopt today if you want one DuckDB to publish a curated, read-mostly dataset to other DuckDBs inside a trusted network. Keep the publisher stateless wherever you can - serve views over durable storage rather than hoarding the durable storage yourself - keep result sets modest, and don't let the network become your application's hot path.
Wait if your workload leans hard on server-side computation across big remote tables. The substrate isn't shaped for that yet. It will be - just not today.
Skip it if your clients aren't DuckDB, if you need streaming or incremental semantics, or if you're trying to face the open internet from behind a managed gateway. There are better-suited tools for each of those, and Quack isn't out to beat them.
The protocol is small; the idea is large. Worth tracking, and worth trying in the places it already fits - because on the day the federated-planner side grows up, the same code you write today quietly gets a great deal more powerful, without a single line changing in your application.